خیلی از ما با دادههایی سر و کار داریم که افراد دیگه برامون فرستادن و خیلی وقتا لازمه بدونیم که دادهها واقعی هستن یا ساختگی. نکته خیلی جالب اینه که چنتا تست خیلی ساده برای این کار وجود داره.
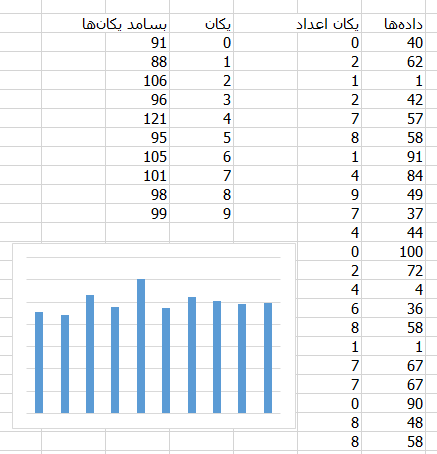
بسامد عدد ۷ در یکان
اگه از آدمای مختلف بخواین که عددی اتفاقی بین ۱ و ۹ انتخاب کنن، خیلی بیشتر از ۱۰ درصدشون عدد ۷ رو انتخاب میکنن. عدد ۷ به نظر همه آدمها اتفاقیترین عدد میاد و به همین خاطر وقتی هم که دارن دادههای ساختگی سر هم میکنن ازش زیاد استفاده میکنن.
برای چک کردن این ماجرا باید به یکان اعداد توجه کنین. اگه مثلا بیست درصدشون ۷ بود، نشون میده که دادهها ساختگی هستن. خیلی راحت!
محاسبه کردنش هم راحته. با تابع MOD اکسل میتونین باقیمانده تقسیم اعداد بر ۱۰ رو به دست بیارین، که میشه یکانشون. با تابع COUNTIF هم میتونین بسامد یکانهای مختلف رو بشمرین.
بسامد یکانها تو این مجموعه عدد اتفاقی یکسانه و در نتیجه فعلا دلیلی نداریم که فکر کنیم ساختگی هستن. ولی تو قسمت بعد میبینیم که ماجرا به این سادگی هم نیست!
قانون بنفرد
اعدادی که تو مثال قبل بود با تابع رندم اکسل ساخته شده بود و کاملا اتفاقی بودن. با این حال اعدادی که از واقعیتهای خارجی استخراج میشن به این شکل رندم نیستن!
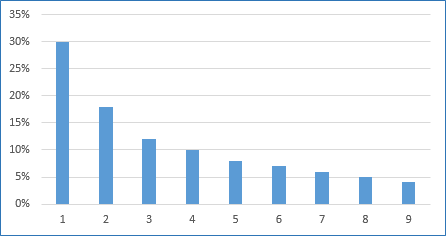
این ماجرا خیلی عجیب و خلاف شهوده، ولی واقعیت داره. یکان اعدادی که از واقعیتهای خارجی استخراج میشن توزیع یکسانی ندارن. اندازهگیری عناصر فیزیکی خارجی، جمعیت شهرها، نتایج رایگیریها (بله، از این روش برای ارزیابی انتخابات ایران هم استفاده شده بود) و خیلی چیزهای دیگه چنین بسامدهایی دارن:
یعنی یکان ۱ که تو اعداد اتفاقی حدود ۱۰٪ مواقع دیده میشه، تو دادههای واقعی ۳۰٪ دیده میشه یا مثلا یکان ۹ که باز هم تو اعداد اتفاقی حدود ۱۰٪ مواقع وجود داره تو دادههای واقعی حدود ۴٪ مواقع به چشم میخوره.
دلیل این ماجرا اینه که عملا اکثر چیزها تو واقعیت طبیعت لگاریتمی دارن و در نتیجه مقادیری که از اونها برداشت میشن هم این رو منعکس میکنن. تو مقیاس لگاریتمی فاصله بین ۱ و ۲ خیلی بیشتر از ۸ و ۹ هست، و به همین خاطر برداشتهای خیلی بیشتری تو اون فاصله قرار میگیره تا فاصله بین ۸ و ۹.
پس راه کاملتر برای بررسی اینکه مجموعهای از دادهها ساختگی هست یا نه اینه که اونها رو با توزیعی که قانون بنفرد توضیح میده مقایسه کنیم. اگه اعداد رو یه کسی ذهنی ساخته باشه یا حتی از یه تابع رندم برای ساختشون استفاده کرده باشه، با این توزیع نمیخونه و به راحتی متوجه میشیم.
در مورد ماجرایی که تو بخش اول در مورد یکان ۷ توضیح دادم هم الان میدونیم که باید انتظار حدودا ۶٪ بسامد ازش داده باشیم و نه حتی ۱۰٪. اگه میخواین سریع نتیجهگیری کنین یه نگاه به یکانها بکنین و ببینین اگه خیلی بیشتر از ۶ بار تو هر ۱۰۰ عدد تکرار شدن، میتونین حدس بزنین که اعداد ساختگی هستن.
وقتی میخواین این ارزیابی رو انجام بدین مراقب باشین که ۱) تعداد اعداد خیلی کم نباشه و ۲) اعداد طبق برنامهریزی قبلی گرد نشده باشن.